Мультизадачность, SMP-системы и кластеры
Само по себе понятие "параллельная обработка" подразумевает такое выполнение программы, при котором несколько инструкций исполняются сразу несколькими процессорами, необязательно центральными (CPU). Например обработка данных будет параллельной и в том случае, если компьютер одновременно ведет расчет и производит запись на жесткий диск. В этих условиях работают и центральный, и периферийный процессоры (контроллер жесткого диска чипсета материнской платы), а время выполнения программы в целом существенно сокращается.
Еще одним шагом на пути увеличения общей производительности систем стало появление мультизадачных операционных систем, которые могут функционировать с одним центральным процессором. Такая ОС выделяет квант процессорного времени для каждой из задач (с учетом их приоритетности), из-за чего у пользователя создается впечатление, что выполнение задач распараллеливается. Несложно догадаться, от мультипроцессорные системы на базе мультизадачных ОС гарантируют наибольший прирост быстродействия. В этом случае борьба приложений за ресурсы практически упраздняется, в результате данные каждого из приложений могут быть обработаны более оперативно.
Идея создания мультипроцессорных мультизадачных вычислительных комплексов не нова и будоражила головы создателей едва ли не со времени появления самых первых ЭВМ. Так, в ранних мультипроцессорных системах их конструкторы пытались организовать мультипроцессорные комплексы таким образом, что связь между процессорами осуществлялась по принципу "главный - подчиненный". В этих условиях главному процессору отводилась задача управления всем комплексом подсистем вычислительного комплекса, тогда как подчиненные выполняли лишь те задания, которые им адресовали. Понятно, что эффективность и скорость работы такой системы из-за больших административных задержек была невысокой. Кроме того в начале эволюции мультипроцессорных систем техника их эффективного программирования не была развита настолько, чтобы предоставить программам возможность задействовать ресурсы кооперативно.
Решение описанной проблемы и привело к созданию симметричных мультипроцессорных систем (Symmetric Multiprocessing - SMP), которые стали сегодня самой распространенной мультипроцессорной архитектурой. Главная особенность таких систем в том, что все процессоры имеют одинаковые права для доступа ко всем системным ресурсам и управлению ими. На практике получается, что все процессоры симметричной системы видят ее ресурсы одинаково, не подозревая о существовании "коллег". Роль администратора в вопросах распределения задач между процессорами отводится операционной системе, которая самостоятельно решает, которой из ветвей задачи нагрузить тот или иной процессор. Так как оперативная память для процессоров также является разделяемым ресурсом, доступ к ней от процессоров должен осуществляться по единой шине. Сразу отметим, что симметричность системы относительно памяти - весьма важное преимущество SMP-систем, ведь в таком случае на всех процессорах может выполняться только одна копия операционной системы. Если все процессоры, которые разделяют системную память, разделяют и единый образ этой памяти (грубо говоря, используют одни и те же "координаты" данных), то говорят о когерентной (согласованной) памяти. На практике же получается, что все процессоры читают байт по одному и тому же адресу и получают одинаковое значение этого байта. Немаловажно, что в процессорах со встроенной кэш-памятью ее содержимое тоже должно быть согласовано с системной памятью. Сегодня существует целый ряд механизмов, позволяющих поддерживать когерентность данных на всех уровнях. Что касается соединения процессоров и контроллера памяти, наиболее распространенное решение заключается в использовании одной системной шины. Впрочем, такая архитектура плохо масштабируется, ведь при увеличении числа процессоров шина становится своеобразным бутылочным горлышком для всей системы. Причем какой бы широкой полоса пропускания в этом случае ни была, ее все равно будет недостаточно, так как одну-единственную физическую шину в определенный момент времени все равно придется делить надвое. Для преодоления ограничения были разработаны другие решения.
Среди них наиболее распространена архитектура с иерархией шин. Несколько процессоров объединяются одной шиной в узел, а узлы подсоединяются к общей более производительной шине, соединяющей их с контроллером памяти и другими контроллерами набора системной логики. Надо сказать, что такой подход наиболее близок к тому, что мы можем видеть в современных мультипроцессорных решениях компании Intel. Впервые SMP-системы на базе процессоров Intel появились в 1993 году. Именно тогда корпорация опубликовала спецификацию MultiProcessor Specification (MPS), в которой очертила будущее мультипроцессорных систем на базе своих процессоров. Главной особенностью этой спецификации стало стремление создать стандартный интерфейс для мультипроцессорной платформы, который позволил бы не только получить решения более производительные, чем однопроцессорные, но и сохранить 100%-ную совместимость с ними. Другое отличие SMP от Intel также в том, что система перестает быть симметричной при загрузке и выключении. В эти моменты один из процессоров назначается процессором загрузки (BootStrap Processor), тогда как остальные - процессорами приложений (Application Processors). В итоге BootStrap Processor несет ответственность за инициализацию системы и загрузку ОС, после чего переименовывается в Application Processor и активирует остальных. Проблема обеспечения корректной работы с аппаратными прерываниями в системах Intel решается с помощью усовершенствованных программируемых контроллеров прерываний (Advanced Programmable Interrupt Controller - APIC), которые встраиваются в каждый элемент системы, предусматривающий генерирование сигнала прерывания. Кроме внешних устройств сигналы прерывания используются также процессорами для межпроцессорных коммуникаций (InterProcessor Interrupts - IPI). Все контроллеры APIC объединяются выделенной шиной межпроцессорных коммуникаций Interrupt Controller Communications bus (ICC bus). Поэтому стоит понимать, что вовсе не процессоры являются "сердцем" SMP-системы.
Куда более важную роль играет набор системной логики. Так, в системах на базе Xeon/Itanium 2 используется одна общая полудуплексная шина, которая в случае интенсивного обращения к ОЗУ становится узким местом. Единственный выход из положения - наличие в процессорах собственного объемного кэша, что, кстати, и объясняет такие стремительные темпы его роста в линейках процессоров Xeon и Itanium 2. Делается это с целью уменьшить количество запросов к оперативной памяти, снизив таким образом латентность обработки запросов к системе в целом. Но существуют и другие решения, позволяющие более эффективно объединять множество процессоров под сводами одной системы. Одно из них подразумевает использование коммутируемой памяти, когда каждый процессор получает доступ к требуемому участку памяти по коммутируемому каналу. Когерентность памяти для коммутируемой архитектуры обеспечить проще, чем для шинной, в результате такие системы лучше масштабируются, а их скорость отклика зачастую оказывается выше. Описанная топология характерна, например, для современных многопроцессорных решений от AMD. Причем инженеры компании пошли даже дальше, разрабатывая решение, способное обработать максимальное количество запросов. Коммутация между процессорами AMD может изменяться в зависимости от того, в какой области памяти находятся необходимые для вычислений данные. Нестандартная организация узла "процессор - память" (контроллер памяти интегрирован в кристалл процессора) в системе AMD предполагает свой принцип построения чипсетов. Так, чипсет под Opteron - AMD-8000 - не содержит привычных северного и южного мостов. Он состоит из так называемых туннелей-контроллеров, имеющих на входе одну полосу пропускания, а на выходе - другую, при этом разница пропускных способностей может использоваться для своих целей. Набор логики поддерживает соединение в цепочку произвольного количества туннелей, что позволяет получать системы различной сложности и с различными характеристиками. Используя возможности шины HyperTransport, AMD-8000 может стать решением для одно-, двух- и восьмипроцессорных систем.
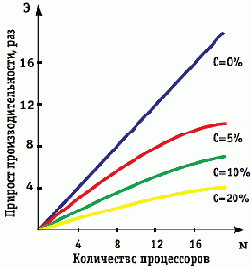
Наибольшее преимущество такого подхода - в практически линейном росте производительности при увеличении количества CPU. Получается, что на подобных системах одинаково хорошо решаются как задачи, оптимизированные для параллельного выполнения на уровне алгоритмов, так и обычные многопоточные приложения. Однако затрагивая вопрос о параллельных вычислениях, нельзя не вспомнить о кластерах. Сегодня развитие технологий широкополосных коммутаций достигло того уровня, когда достаточно эффективно соединить несколько компьютеров оказывается не так сложно и дорого, как обзавестись законченным многопроцессорным решением. При этом, помимо меньшей стоимости по сравнению с многопроцессорными системами, несложные кластеры предлагают еще и более эффективную обработку многопоточных приложений, чем в архитектуре с иерархией шин (подход Intel). Чтобы убедиться в этом, достаточно обратиться к закону Амдала (Amdahl's law), который связывает производительность отдельно взятого вычислителя (узла кластера) с высокоуровневой архитектурой. Фактически его можно считать фундаментальной оценкой максимальной производительности абстрактной параллельной вычислительной машины. Не вдаваясь в подробности теории Джина Амдала (Gene Myron Amdahl), скажем, что формулировка закона гласит о том, что эффективность кластера зависит от двух параметров - количества процессоров и доли последовательных операций в программе (зависимость не линейна). Следствие из закона Амдала: идеальная характеристика прироста производительности (в n раз при n процессорах) в реальности недостижима, так как возможна лишь в случае, когда последовательно исполняемая часть программы равна нулю. Наиболее важные выводы из закона Амдала заключаются в следующем. Первый: при достаточно большой доле нераспараллеливаемых команд (С=20%) в коде программы после определенного числа вычислителей (20) наблюдается прекращение роста производительности. Это отражено на . Второй: наиболее эффективный способ повышения производительности - не увеличение числа вычислителей, а алгоритмическое совершенствование задач.
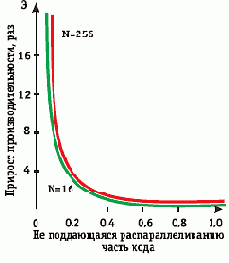
Это особенно хорошо заметно, если закон Амдала представить в виде зависимости прироста производительности от процента содержания нераспараллеливающейся части кода ().